How to create a web service that will interact with users in real time while supporting several hundred thousand connections at the same time?
Hello everyone, my name is Andrey Klyuev, and I’m a developer. Recently, I faced a task to create an interactive service where users can receive quick bonuses for their actions. The task was complicated by the fact that the project had rather high requirements for the load, and the time limits were extremely short.
In this article, I will tell you how I chose a solution for implementing a web-socket server for the difficult requirements of the project, what problems I encountered during the development process, and I will also say a few words about how configuring the Linux kernel can help achieve the above mentioned goals.
Useful links to development, testing, and monitoring tools are provided at the end of the article.
TASKS AND REQUIREMENTS
Requirements to the functionality of the project:
- make it possible to track the user’s presence on the resource and track browsing time;
- ensure fast messaging between the client and the server, since the time for the user to receive the bonus is strictly limited;
- create a dynamic interactive interface with synchronization of all actions when the user works with the service through several tabs or devices simultaneously.
Load requirements:
- The app must withstand at least 150,000 online users.
Implementation period – 1 month.
TECHNOLOGY CHOICE
Having compared the tasks and requirements of the project, I came to the conclusion that it is most expedient to use WebSocket technology for the project development. It provides a permanent connection to the server, eliminating the overhead for a new connection with each message, which is present while ajax and long-polling based technologies are used. This allows you to get the necessary high speed messaging, combined with adequate resource consumption, which is very important under high loads. Also, due to the fact that connection and connection abort are two distinct events, it becomes possible to accurately track the time a user is on the site.
Given the rather limited time frame for the project, I decided to use the WebSocket framework. I studied several options, and PHP ReactPHP, PHP Ratchet, Node.JS websockets / ws, PHP Swoole, PHP Workerman, Go Gorilla, Elixir Phoenix seemed the juiciest to me. I tested their capabilities in terms of load on a laptop with an Intel Core i5 processor and 4 GB of RAM (such resources were quite enough for the study).
PHP Workerman is an asynchronous event-driven framework. Its capabilities are limited to the simplest implementation of a web-socket server and the ability to work with the libevent library which is necessary for processing asynchronous event notifications. The code is at PHP 5.3 level and does not conform to any standards. For me, the main disadvantage was that the framework does not allow the implementation of high-load projects. On the test bed, the developed application of the “Hello World” level was not able to hold even a thousand of connections.
ReactPHP and Ratchet are generally comparable to Workerman in ways of their capabilities. Ratchet depends on ReactPHP internally, it also works through libevent and does not allow you to create a solution for high loads.
Swoole is an interesting framework written in C. It connects as an add-on for PHP and has tools for parallel programming. Unfortunately, I found that the framework was not stable enough: on the test bed, it broke every second connection.
Next, I looked at Node.JS WS. This framework showed good results – about 5 thousand connections on the test bed without additional settings. However, my project involved distinctively higher loads, so I opted for Go Gorilla + Echo Framework and Elixir Phoenix. These options were tested in greated detail.
LOAD TESTING
The purpose of testing was to study the CPU and memory resources consumption. The specifications of the machine were the same – an Intel iCore 5 processor and 4 GB of RAM. The tests were carried out on the example of the simplest chats on Go and Phoenix:
Here is a simple chat application that functioned normally on a machine of the specified capacity with a load of 25-30 thousand users:
config:
target: "ws://127.0.0.1:8080/ws"
phases
-
duration:6
arrivalCount: 10000
ws:
rejectUnauthorized: false
scenarios:
-
engine: “ws”
flow
-
send “hello”
-
think 2
-
send “world”Class LoadSimulation extends Simulation {
val users = Integer.getInteger (“threads”, 30000)
val rampup = java.lang.Long.getLong (“rampup”, 30L)
val duration = java.lang.Long.getLong (“duration”, 1200L)
val httpConf = http
.wsBaseURL(“ws://8.8.8.8/socket”)
val scn = scenario(“WebSocket”)
.exes(ws(“Connect WS”).open(“/websocket?vsn=2.0.0”))
.exes(
ws(“Auth”)
sendText(“““[“1”, “1”, “my:channel”, “php_join”, {}]”””)
)
.forever() {
exes(
ws(“Heartbeat”).sendText(“““[null, “2”, “phoenix”, “heartbeat”, {}]”””)
)
.pause(30)
}
.exes(ws(“Close WS”).close)
setUp(scn.inject(rampUsers(users) over (rampup seconds)))
.maxDuration(duration)
.protocols(httpConf)Test runs have shown that everything works smoothly on a machine of the specified capacity with a load of 25-30 thousand users.
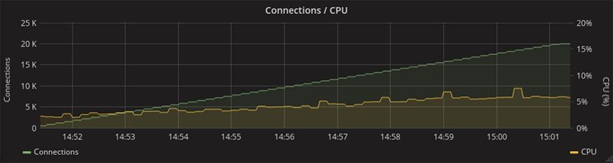
CPU Resource Consumption:
Phoenix
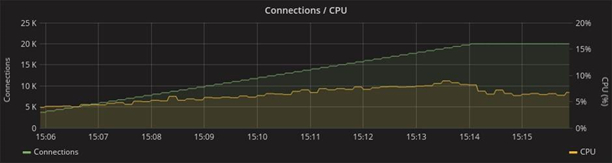
Gorilla
The RAM consumption with a load of 20 thousand connections reached 2 GB in the case of both frameworks:
Phoenix
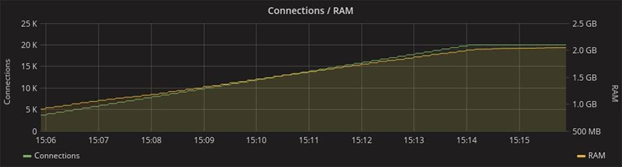
Gorilla
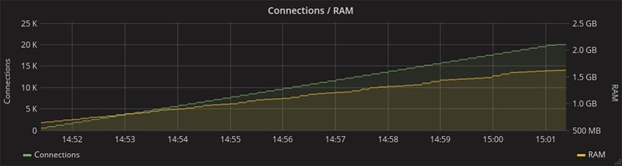
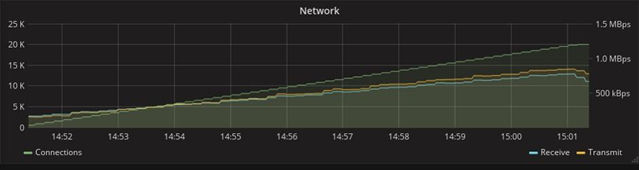
With this in mind, Go even outperforms Elixir, but the Phoenix Framework provides much more features. In the graph below, which shows the consumption of network resources, you can see that 1.5 times more messages are transmitted in the Phoenix test. This is due to the fact that this framework in the original “boxed” version already has a mechanism for heartbeats (periodic synchronization signals), which by using Gorilla will have to be implemented independently. Given the tight deadline, any additional work was a strong argument in Phoenix’s favour.
Phoenix
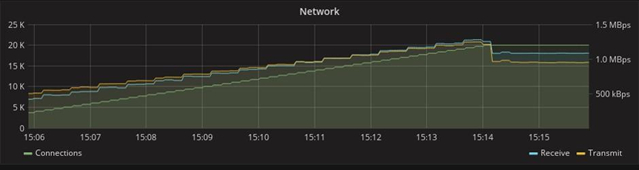
Gorilla
ABOUT THE PHOENIX FRAMEWORK
Phoenix is a classic MVC framework that is fairly similar to Rails. It’s no marvel since one of its developers and the creator of the Elixir language is José Valim, one of the main creators of Ruby on Rails. Even the syntax shows some similarities.
Phoenix:
defmodule Benchmarker.Router do
use Phoenix.Router
alias Benchmarker.Controllers
get "/:title", Controllers.Pages, :index, as: :page
endRails:
Benchmarker::Application.routes.draw do
root to: "pages#index"
get "/:title", to: "pages#index", as: :page
endMIX IS AN AUTOMATION UTILITY FOR ELIXIR PROJECTS
When using Phoenix and the Elixir language, much of the work is done through the Mix utility. This is a build tool that solves many different tasks for creating, compiling and testing an application, managing its dependencies and some other processes.
Mix is a key part of any Elixir project. This utility is on par to analogues from other languages, but it does its job perfectly well. And due to the fact that the Elixir code runs on the Erlang virtual machine, it becomes possible to add any libraries from the Erlang world as dependencies. In addition, along with Erlang VM, you get convenient and safe parallelism, as well as high fault tolerance.
PROBLEMS AND SOLUTIONS
With all the advantages, Phoenix has its drawbacks. One of them is the difficulty of solving such a task as tracking active users on the site under high load.
The fact is that users can connect to different application nodes, and each node will only know about its own clients. To display a list of active users, you will have to poll all the nodes of the application.
To solve these problems, Phoenix has a Presence module that gives the developer the ability to track active users in just three lines of code. It uses the mechanism of heartbeats and conflict-free replication within the cluster, as well as a PubSub-server for messaging between nodes.
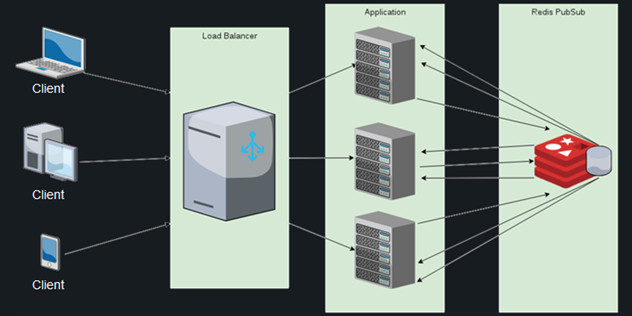
It sounds awesome, but in reality it turns out the following. Hundreds of thousands of connecting and disconnecting users generate millions of messages for synchronization between nodes, due to which the consumption of processor resources exceeds all acceptable limits, and even connecting Redis PubSub does not save the day. The list of users is duplicated on each node, and the calculation of the differential with each new connection becomes more and more expensive – and this is considering that the calculation is carried out on each of the active nodes.
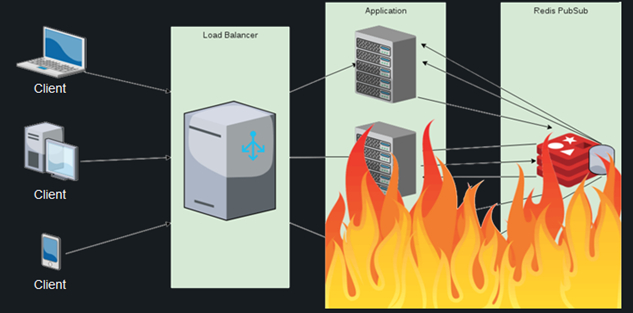
In such a situation, the mark of even 100 thousand customers becomes unattainable. I could not find other ready-made solutions for this task, so I decided to do the following: assign the responsibility for monitoring the presence of users online to the database.
At first glance, this is a good idea, and has nothing complicated in it: it is enough to store the last activity field in the database and periodically update it. Unfortunately, for projects with a high load, this is not an option: when the number of users reaches several hundred thousand mark, the system will not be able to cope with the millions of heartbeats coming from them.
I chose a less trivial but more productive solution. When a user connects, a unique row is created for him in the table, which stores his identifier, the exact time of entry and the list of nodes to which the user is connected. The list of nodes is stored in a JSONB-field, and in case of a string conflict, it is enough to update it.
create table watching_times (
id serial not null constraint watching_times_pkey primary key,
user_id integer,
join_at timestamp,
terminate_at timestamp,
nodes jsonb
);
create unique index watching_times_not_null_uni_idx
on watching_times (user_id, terminate_at)
where (terminate_at IS NOT NULL);
create unique index watching_times_null_uni_idx
on watching_times (user_id)
where (terminate_at IS NULL);Here is a request for logging in a user:
INSERT INTO watching_times (
user_id,
join_at,
terminate_at,
nodes
)
VALUES (1, NOW(), NULL, '{nl@192.168.1.101”: 1}')
ON CONFLICT (user_id)
WHERE terminate_at IS NULL
DO UPDATE SET nodes = watching_times.nodes ||
CONCAT(
'{nl@192.168.1.101:',
COALESCE(watching_times.nodes->>'nl@192.168.1.101', '0')::int + 1,
'}'
)::JSONB
RETURNING id;Here is how the node list looks like:

If the user opens the service in a second window or on another device, he can get to another node, and then it will also be added to the list. If it hits the same node as in the first window, the number next to the name of this node in the list will increase. This number reflects the number of active user connections to a particular node.
This is how the query that goes to the database when the session is closed looks like:
UPDATE watching_times
SET nodes
CASE WHEN
(
CONCAT(
'{“nl@192.168.1.101”: ',
COALESCE(watching_times.nodes ->> 'nl@192.168.1.101', '0') :: INT - 1,
'}'
)::JSONB ->>'nl@192.168.1.101'
)::INT <= 0
THEN
(watching_times.nodes - 'nl@192.168.1.101')
ELSE
CONCAT(
'{“nl@192.168.1.101”: ',
COALESCE(watching_times.nodes ->> 'nl@192.168.1.101', '0') :: INT - 1,
'}'
)::JSONB
END
),
terminate_at = (CASE WHEN ... = '{}' :: JSONB THEN NOW() ELSE NULL END)
WHERE id = 1;List of nodes:

When a session is closed on a certain node, the connection counter in the database is reduced by one, and when it reaches zero, the node is removed from the list. When the list of nodes is completely empty, this moment will be fixed as the final exit time of the user.
This approach made it possible not only to track the user’s online presence and browsing time, but also to filter these sessions by various criteria.
Throughout it all, there is only one drawback – if a node falls, all its users “freeze” online. To solve this problem, we have a daemon that periodically cleans the database of such records, but so far this has not been required. The load analysis and monitoring of the cluster operation, carried out after the project went into production, showed that there were no node crashes, and this mechanism was not used.
There were other difficulties, but they are more specific, so it’s worth moving on to the issue of application fault tolerance.
CONFIGURING THE LINUX KERNEL FOR IMPROVING PERFORMANCE
Writing a good application in a performance language is only half the battle, without competent DevOps it is impossible to achieve any significant results.
The first obstacle on the way to the target load was the Linux network kernel. It took some tweaking to make better use of its resources.
Each open socket is a file descriptor in Linux, and their number is limited. The reason for the limit is that for each open file in the kernel, a C structure is created that occupies unreclaimable-kernel memory.
File descriptor limits:
#!/usr/bin/env bash
sysctl -w 'fs.nr_open=10000000' # Максимальное количество открытых файловых дескрипторов
sysctl -w 'net.core.rmem_max=12582912' # Максимальный размер буферов приема всех типов
sysctl -w 'net.core.wmem_max=12582912' # Максимальный размер буферов передачи всех типов
sysctl -w 'net.ipv4.tcp_mem=10240 87380 12582912' # Объем памяти TCP сокета
sysctl -w 'net.ipv4.tcp_rmem=10240 87380 12582912' # размер буфера приема
sysctl -w 'net.ipv4.tcp_wmem=10240 87380 12582912'# размер буфера передачи
sysctl -w 'net.core.somaxconn=15000' # Максимальное число открытых сокетов, ждущих соединенияIf you are using nginx in front of a cowboy-server, then you should also think about increasing its limits. The worker_connections and worker_rlimit_nofile directives are responsible for this.
The second obstacle is not so obvious. If you run such an application in distributed mode, you can notice a sharp increase in processor resource consumption with an increase in the number of connections. The problem is that Erlang by default works with Poll system calls. Version 2.6 of the Linux kernel has Epoll which can provide a more efficient mechanism for applications that handle a large number of simultaneously open connections – with O(1) complexity, as opposed to Poll, which has O(n) complexity.
Fortunately, Epoll mode is enabled with a single flag: +K true, I also recommend increasing the maximum number of processes spawned by your application and the maximum number of open ports using the +P and +Q flags, respectively.
Poll vs. Epoll
#!/usr/bin/env bash
Elixir --name ${MIX_NODE_NAME}@${MIX_HOST} --erl “-config sys.config -setcookie ${ERL_MAGIC_COOKIE} +K true +Q 500000 +P 4194304” -S mix phx.serverThe third obstacle is more individual, and not everyone can face it. This project faced the process of automatic deployment and dynamic scaling organized by using Chef and Kubernetes. Kubernetes allows you to quickly deploy Docker-containers on a large number of hosts, and this is very convenient. However, it is impossible to find out the IP-address of the new host in advance, and if you do not register it in the Erlang config, you will not be able to connect the new node to the distributed application.
Fortunately, the libcluster library exists to solve these problems. Communicating with Kubernetes via API, it learns in real time about the creation of new nodes and registers them in the erlang cluster.
config :libcluster,
topologies: [
k8s: [
strategy: Cluster.Strategy.Kubernetes,
config: [
kubernetes_selector: “app=my -backend”,
kubernetes_node_basename: “my -backend”]]]RESULTS AND PROSPECTS
The chosen framework combined with the correct configuration of the servers made it possible to achieve all the goals of the project: to develop an interactive web-service within the set timeframe (1 month) that communicates with users in real time and at the same time withstand loads of 150,000 connections and more.
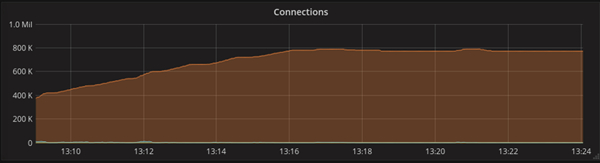
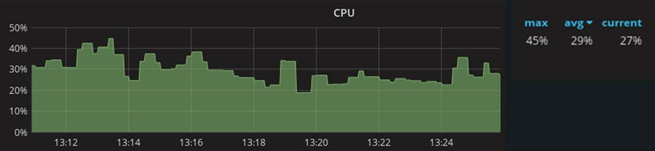
After the launch of the project in production, monitoring was carried out which showed the following results: with a maximum number of connections up to 800 thousand, the consumption of processor resources reaches 45%. The average load value is 29% with 600 thousand connections.
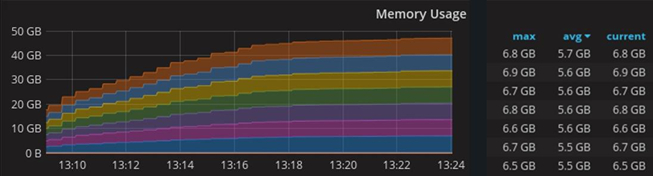
This graph shows memory consumption when working in a cluster of 10 machines with 8 GB of RAM each.
As for the main working tools in this project, Elixir and Phoenix Framework, I have every reason to believe that in the coming years they will become as popular as Ruby and Rails used to be, so it makes sense to start mastering them now.
Thank you for your attention!
